分析了一下b站的视频评论接口
接口地址:YXBpLmJpbGliaWxpLmNvbS94L3YyL3JlcGx5L3diaS9tYWlu
考完试无聊分析了一下,发现还挺简单的,新手勿喷。
F12看一下请求参数:
1 | ?oid=115818021131687 |
简单调试分析得出:
- oid是视频aid,从视频网页页面(/video/{bvid}/?spm_id_from=333.1007.tianma.6-3-19.click)中提取
- seed_rpid、type、mode、plat、web_location(1315875)固定
- offset由返回值里提供,第一次为空,CAESEDE4MTAxODA0NTU3MzU0NTgiAggB
- w_rid每次请求都在变化,需要分析
- wts是秒级Unix时间戳
w_rid分析:先根据请求堆栈打上断点,运行到下面的位置,证明调试方向没有问题,然后继续单步调试
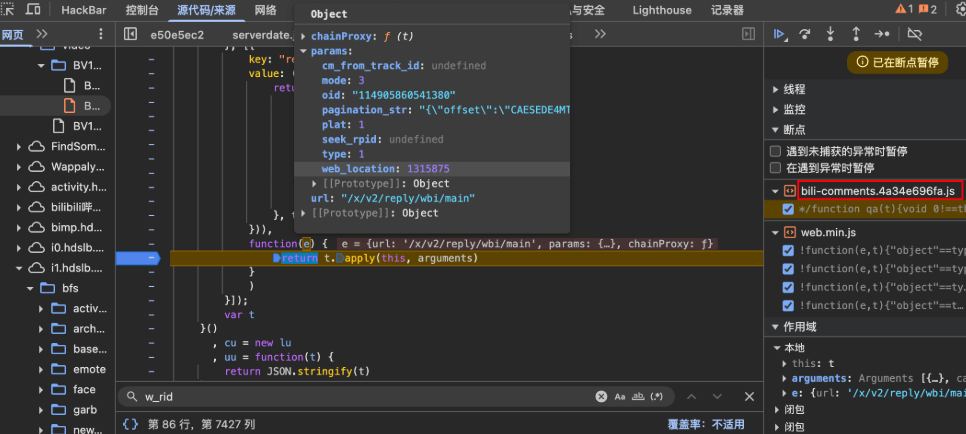
调试到下面位置,确认wts为时间戳,计算方式为Math.round(Date.now() / 1000),w_rid为at(v+a)
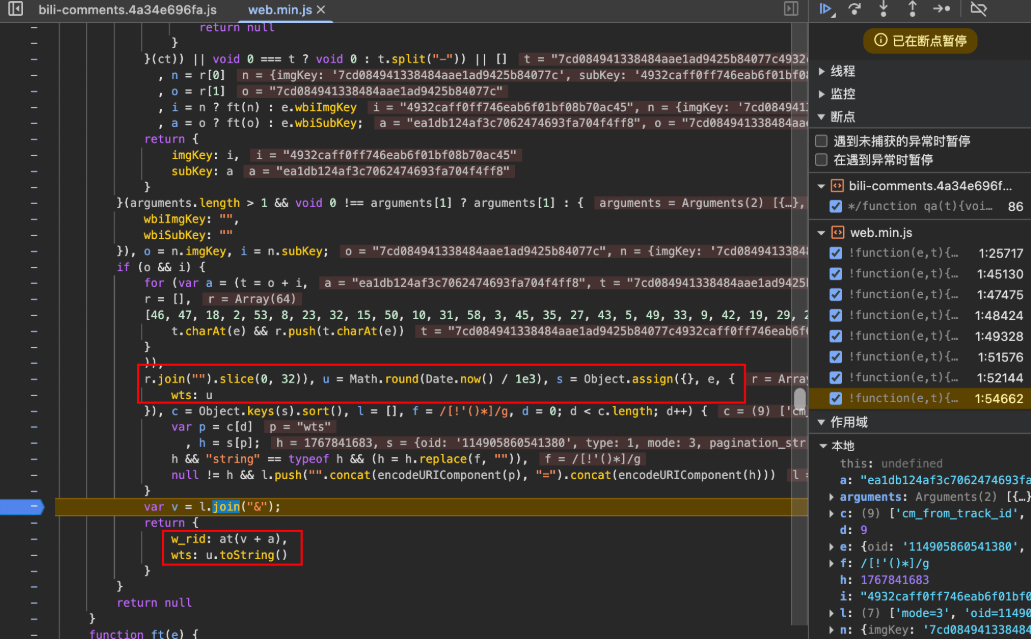
这里v为前面所有已知请求字段的拼接字符串:这里注意参数排序不能变,以及pagination_str字段一定要url编码后再拼接
第一次请求:
1 | ?mode=3&oid=114905860541380&pagination_str=%7B%22offset%22%3A%22%22%7D&plat=1&seek_rpid=&type=1&web_location=1315875&wts=1767841683 |
后续请求:
1 | ?mode=3&oid=114905860541380&pagination_str=%7B%22offset%22%3A%22CAESEDE4MTAyNjYxNzg2MTEzNTQiAggB%22%7D&plat=1&type=1&web_location=1315875&wts=1767841762 |
a的计算方式如下,其中o = n.imgKey, i = n.subKey;,这两个key是在前面计算的,等会倒回去再看。
1 | var a = ( |
这是一个对字符串 t = o + i 做固定索引重排,然后取前 32 位作为签名值的算法。下面是分析at(v+a):r作为缺省值输入,

标准MD5:四个常量是 MD5 的标志性特征:
1 | c = 1732584193 → 0x67452301 |
这是 RFC 1321 定义的 MD5 初始状态,SHA1、SHA256 都不使用这组值。
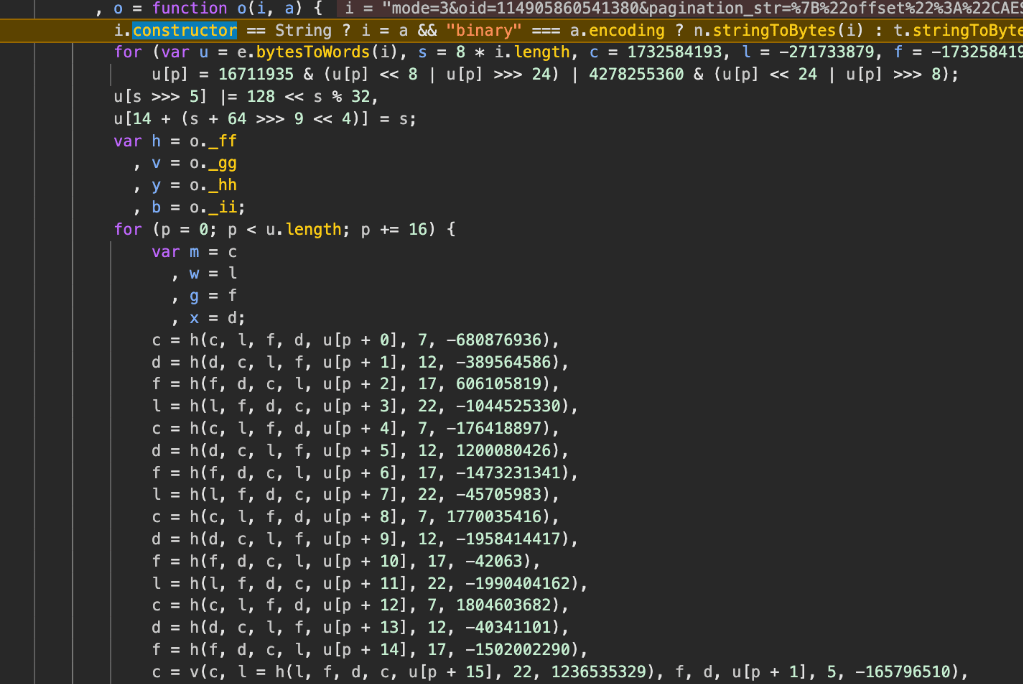
经过验证,完全没问题:
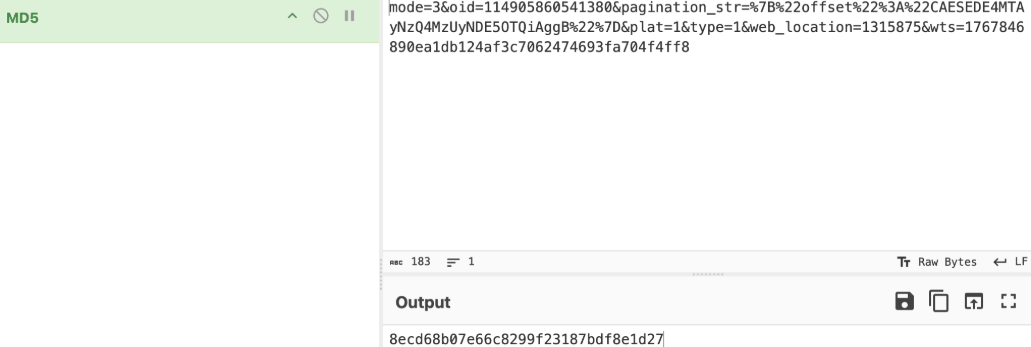
那么也就是说w_rid=MD5(v+a),那现在需要搞定解决生成a的两个key的计算方法。往前看看,imgkey和subkey有两种,一个是useAssignKey存在,直接赋值wbi*的值;不存在就提取两个url链接中的值。
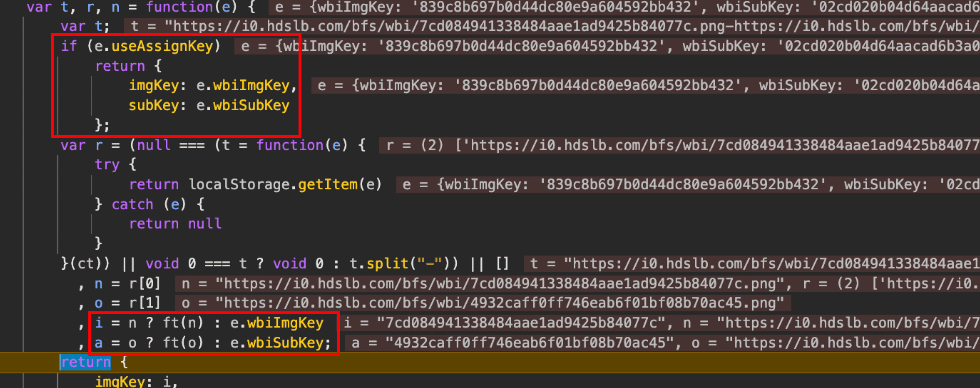
wbi*这两个key硬编码在前端代码里,但是多次测试后,发现后续分支控制不走这个赋值。
1 | encWbiKeys: { |
然后多次测试后发现imgKey=7cd084941338484aae1ad9425b84077c和subKey=4932caff0ff746eab6f01bf08b70ac45似乎是固定的,然后页走这个分支赋值。那么a的值就是固定的。但还是可以扣出a的生成代码:
1 | def generate_sign_key( o: str = imgKey, i: str = subKey) -> str: |
解析评论接口返回的消息结构:
1 | { |
这里发现只能爬取一页,原来是后续请求不需要seek_rpid字段,包括前面生成w_rid的时候。
后续页面请求:
1 | /x/v2/reply/wbi/main?oid=115540727170621&type=1&mode=3&pagination_str=%7B%22offset%22:%22CAESEDE4MTAzNTI4NTE1OTMwNzQiAggB%22%7D&plat=1&web_location=1315875&w_rid=cf9f98cf24cc1b98d38e3c1d599262d6&wts=1767923353 |
第一页请求:
1 | /x/v2/reply/wbi/main?oid=115540727170621&type=1&mode=3&pagination_str=%7B%22offset%22:%22%22%7D&plat=1&seek_rpid=&web_location=1315875&w_rid=d7e302b0dc95323e49f77ec5ffc7ebcf&wts=1767922706 |
最后编写代码,成功获取,次级评论接口很简单,这里不写了。