论文阅读1
本文最后更新于:2024年9月27日 下午
The Great Request Robbery: An Empirical Study of Client-side Request Hijacking Vulnerabilities on the Web
伟大的请求劫持:对网络客户端请求劫持漏洞的实证研究
关于为什么这里使用请求劫持这个词而不是伪造,个人分析,伪造是手段,目的是为了达到劫持这种状态,想一想,攻击者能够伪造受害者发出请求,怎么不算劫持了受害者的请求呢。
Abstract
原文翻译
请求伪造攻击是Web应用程序最古老的威胁之一,传统上是由服务器端混淆的代理漏洞引起的。然而,最近客户端技术的进步引入了更微妙的请求伪造变种,攻击者利用客户端程序中的输入验证缺陷来劫持发出请求。我们几乎没有关于这些客户端变体的信息,它们的流行程度,影响和对策,在本文中,我们对Web平台上客户端请求劫持的状态进行了第一次评估。
从全面审查浏览器API功能和Web规范开始,我们将请求劫持漏洞和由此导致的攻击系统化,确定了10个不同的漏洞变体,其中包括7个新的漏洞。然后,我们使用我们的系统设计和实现了Sheriff,一个静态-动态工具,用于检测从攻击者可控输入到请求发送指令的脆弱数据流。
我们在Tranco Top 10K网站的顶部实例化了Sheriff,据我们所知,这是对野外普遍存在的请求劫持缺陷的首次调查。我们的研究发现,请求劫持漏洞无处不在,影响了9.6 %的前10K站点。我们通过在49个站点上构建67个概念验证漏洞,展示了这些漏洞的影响,使得针对Microsoft Azure、Starz、Reddit和Indeed等流行网站的任意代码执行、信息泄露、开放重定向和CSRF成为可能。最后,我们回顾和评估了针对客户端请求劫持攻击的现有对策的采用和有效性,包括基于浏览器的解决方案,如CSP,COOP和COEP,以及输入验证。
重要信息
近几年出现了很多最新的请求劫持的攻击模式,目前还没有对这些方法的系统性研究。通过审查浏览器API功能和Web规范,我们将请求劫持攻击重新分为10类,包括新的7个漏洞。我们开发了Sheriff工具,用于检测网站是否存在请求劫持漏洞,这是对在野请求劫持漏洞的首次调查。通过工具扫描大量站点发现,请求劫持漏洞无处不在。最后,我们评估了现有防御措施的有效性。
Introduction
重要信息
主要介绍了传统请求劫持造成的危害,比如客户端代码执行、混淆请求、删除数据库等等。
最近客户端技术的快速演进引入了更隐蔽的请求伪造漏洞变种,攻击者不再依赖混淆的代理缺陷,而是利用客户端JavaScript程序中的输入验证漏洞来劫持外出请求。目前的研究主要集中在CSRF及相应的检测分析技术。但是不仅仅是CSRF攻击需要被研究,它仅仅是较大的一个版块,还有许多存在于JS代码中的请求可以被劫持。
同样的,最近的研究主要是关注到异步请求,像XMLHttpRequest和Fetch API,忽略了其他类型的请求诸如push notification、web sockets等等。再者,目前的防御策略只解决了混淆代理问题,但新的客户端输入缺陷导致的请求劫持将会绕过目前的防御手段。
在本文中,我们首次对客户端请求劫持漏洞进行了评估,主要包括三个方面:对攻击面的系统探索,对脆弱网站的测量,以及对请求劫持防御的全面审查和评估。然后,我们提出了Sheriff,这是一种客户端请求劫持检测工具,它结合使用混合程序分析和浏览器内动态污点跟踪来发现潜在脆弱的数据流并进行动态分析用于自动漏洞验证的API工具。
重要名词简介
fetch:JS中的函数,用于向服务端请求资源。子请求受到浏览器的同源策略和其他安全限制的保护,因为它们是在同一页面上执行的。
XMLHttpRequest:一个内建的浏览器对象,它允许使用 JavaScript 发送 HTTP 请求。两种执行模式:同步(synchronous)和异步(asynchronous)。子请求受到浏览器的同源策略和其他安全限制的保护,因为它们是在同一页面上执行的。
Top-level Request:顶级请求是指在浏览器中执行的导航请求,例如使用location.assign()、window.open()或通过用户在地址栏中输入URL来导航到新页面的请求。在顶级请求中,浏览器会将当前域下的Cookie发送到目标域。这可能会引发安全问题,特别是如果目标域是恶意站点,它可能会收集和滥用来自其他域的Cookie信息。
CSRH:Client-side Request Hijacking
漏洞描述
CSRH漏洞描述:攻击者可以欺骗受害者的客户端使用攻击者自制的输入来操作发送请求的API。比较出名的漏洞实例像是CSRF这种。
在Microsoft Azure网页中发现的一个可以被劫持的top-level HTTP请求
1 | |
威胁模型
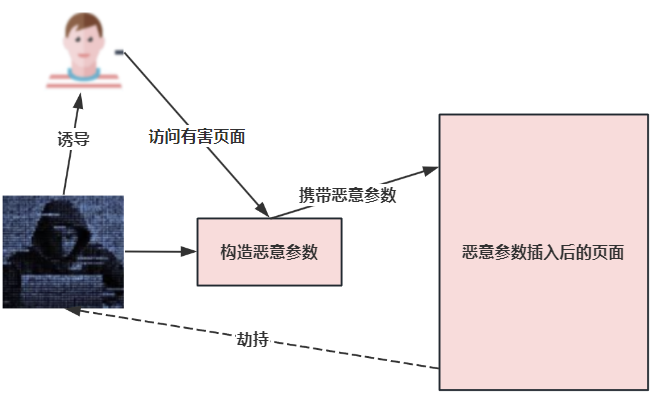
上述漏洞的利用实例:
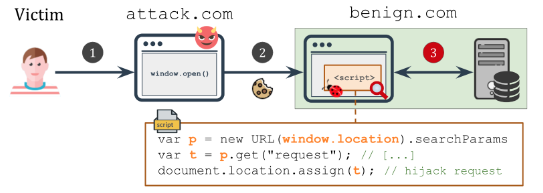
攻击者准备了一个恶意页面并诱导受害者去访问(或者直接分享给受害者存在漏洞的页面,个人觉得这个不如前面那个方法,前面那个方法可以隐藏恶意payload),这个页面会打开存在漏洞的页面,并且此时已经插入了恶意的请求参数,当新的页面加载完成时,上面那段JS代码会加载恶意参数并发出top-level请求,由于是顶级请求,浏览器会获取cookie,从而绕过同源策略,劫持原始请求。
在这篇文章中,研究者们不仅仅关注http形式的URL,例如像location.assign()这种API也可以接收URL。劫持了API后,攻击者将会扩大危害,例如CSRF、客户端代码执行、重定向等等
问题陈述——即本篇论文解决的问题
RQ1:浏览器功能带来的攻击系统化分析
我们研究用于发送请求的各种浏览器方法和 API,并用特定功能标记每个方法和 API(例如,接受 javascript URI、允许设置请求正文等)。然后,我们回顾现有文献并进行全面的威胁建模分析,系统地评估攻击者可以操纵请求发送 API 的各个领域时出现的安全风险。
RQ2:漏洞检测、漏洞存在率及其危害
毫无疑问可以推出,我们对真实网站中请求劫持这一更广泛问题的总体影响和普遍性几乎没有任何信息。
在本文中,我们的目标是通过量化野外请求劫持的普遍程度、识别易受攻击的行为并调查其影响来填补这一空白,以深入了解影响 Web 应用程序安全状况的根本问题和因素。
RQ3:防护措施及其有效性
当前许多研究的重点只是利用混淆代理缺陷的传统请求伪造攻击,因此,我们仍然缺乏对各种防御机制针对请求劫持客户端变体保护范围的全面了解。
API功能带来的攻击的系统化分析——对RQ1的讨论
浏览器API功能
本文的研究者们从WHATWG 和W3C的存储库中进行了系统性的搜索,重点搜索了其中能创建网络请求的JS API,最后选出了6大类一共10个API。这些API都有不同的特点,并默认受到某些约束,例如同源策略。研究者们认为,加入CSP、COOP等额外策略并不能影响到底层软件的缺陷。在本节,本文的研究者们聚焦在这些默认受到约束的API,希望发现默认设置下的可能攻击方式。
研究者们探索出来的10种API:
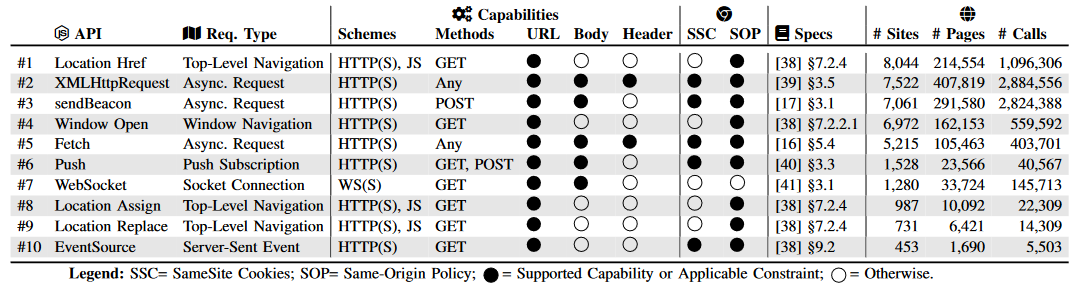
CSRH攻击的系统分析
基于第2.2节的威胁模型:攻击者可以控制4.1节中提出的API发出的网络请求中的URL(在这里可以认为是请求头和请求体)
本文的研究者通过系统地分析前人的资料,并检验了那些由于攻击者能够操纵每个发送请求API的不同字段所带来的潜在攻击。结果发现了一共10种CSRH攻击变体,并且其中只有3种被熟知。

以下列出几种脆弱的API及其存在风险:
异步请求(Asynchronous Requests):
像XMLHttpRequest或者低层次fetch这种没有造成顶层页面重载的异步请求都被常用于和web服务通信。攻击者操纵URL、body和header等等都能导致客户端出现不可控的行为,代表就是CSRF攻击。这种攻击方式可以产生信息泄露,攻击者将受害者的敏感信息如登录凭证包含在请求体中,发送到有害的主机。
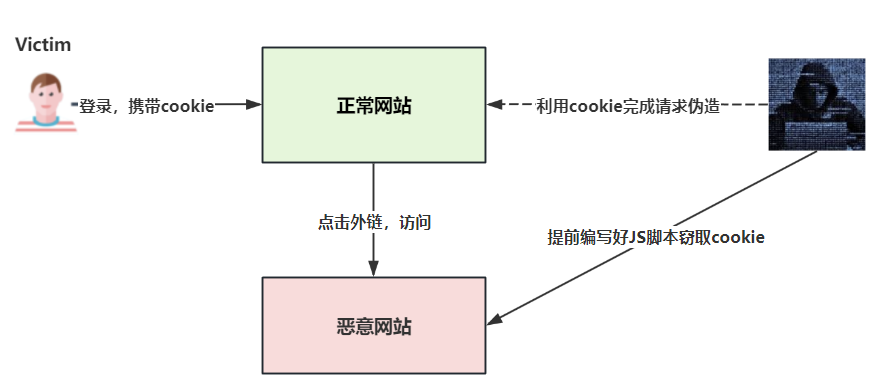
推送请求(Push Request):
Web Push API是一种用于实现推送通知功能的Web标准API。它允许网站向用户的设备(如桌面浏览器或移动设备)发送实时通知,即使用户当前没有打开该网站。当推送订阅没有做好CSRF防护时,会产生CSRF攻击。
服务工作者是一个JavaScript脚本,运行在浏览器的后台,独立于网页。它充当推送通知的中间人,处理接收到的推送消息并显示通知。
参考谷歌推送接口劫持实例,没有做好CSRF防御的PushRequest接口导致的经典CSRF攻击,从而造成用户信息泄露。攻击手段我画了下面这张图:
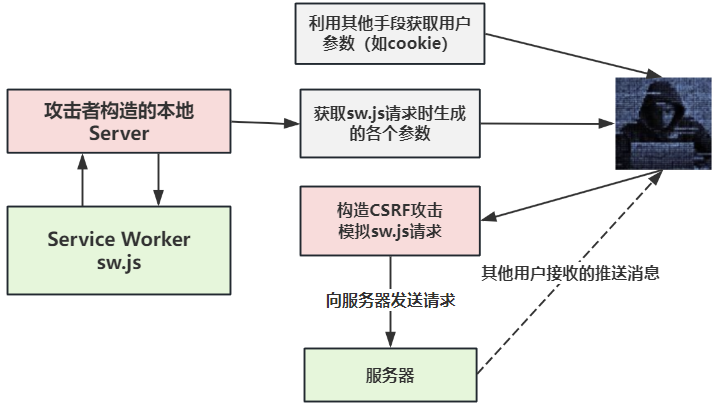
关于论文中提到的推送API造成的客户端DOS,我没有发现公开的实例,只能作出下面的猜测:攻击者通过某种手段获取到了用户在某网站的cookie后,通过模拟sw.js请求,请求大量推送,从而对目标浏览器造成DOS攻击。
服务端发送事件(Server-Sent Events):
SSE是一种服务端向浏览器推送消息的单向通信机制,而Push Request API则是一种允许客户端发起请求并接收服务器推送消息的双向通信机制。
原文中说攻击者操纵参数就可以实现劫持,这里没有看到合适的实例或者更清晰的解释。好像国内外对此研究或者攻击都比较少。先放在这里。
Web Sockets:
WebSocket是一种在Web应用程序中实现双向通信的协议和API。它提供了一种持久化的连接,允许服务器和客户端之间进行实时的双向数据传输。WebSocket通过建立一条持久化的连接,避免了每次通信都需要创建新的HTTP请求的开销。一旦连接建立,服务器和客户端之间可以长时间保持连接状态,实现实时通信。
WebSocket和HTTP的区别:大多数的Web浏览器和Web网站都是使用HTTP协议进行通信的。通过HTTP协议,客户端发送一个HTTP请求,然后服务器返回一个响应。通常来说,服务端返回一个响应后,这个HTTP请求事务就已经完成了。即使这个HTTP连接处于keep-alive的状态,它们之间的每一个工作(事务)依然是请求与响应,请求来了,响应回去了。这个事务就结束了。所以通常来说,HTTP协议是一个基于事务性的通信协议。
而WebSocket呢,它通常是由HTTP请求发起建立的,建立连接后,会始终保持连接状态。客户端和服务端可以随时随地的通过一个WebSocket互发消息,没有所谓事务性的特点。这里要注意了,源于其双向全双工的通信特点,在一个WebSocket连接中,服务端是可以主动发送消息的哦,这一点已经完全区别于HTTP协议了。
因此,基于以上特点,WebSocket通常用于低延迟和允许服务器发送消息的场景。例如,金融行业常用WebSocket来传输实时更新的数据
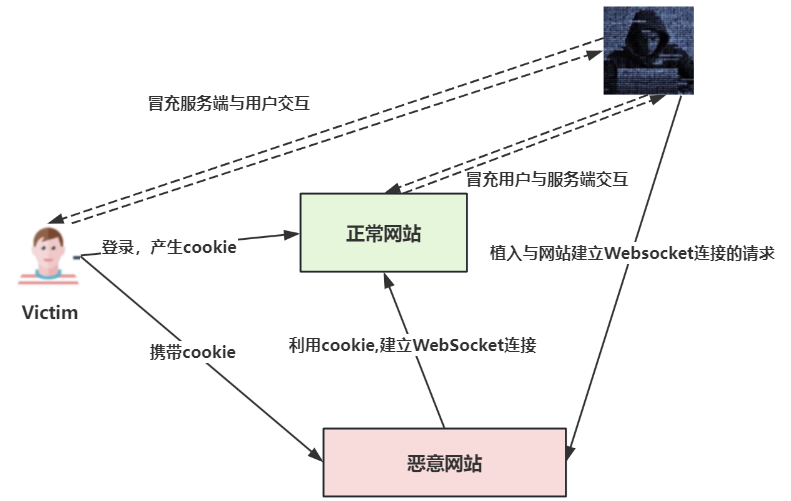
这篇文章的研究者提出,攻击者在控制了WebSocket连接的情况下,可以作为中间人,连接受害者和目标服务器。
参考利用CSWH漏洞实现用户密码重置实例,没有做好CSRF防御导致的攻击。攻击手段我画了下面这张图:
顶级导航请求(Top-Level Navigation Requests):
前面的案例已经研究过了,浏览器的顶层API导致重定向到恶意页面。
窗口导航请求(Window Navigation Requests):
类似location API,前面已经分析过了。
不同API的流行程度
研究者发现 9,901 个域至少包含一个与客户端请求相关的 API,在约 100 万个网页中总共有约 790 万次 API 调用。通过location.href的顶级导航请求最为普遍,出现在超过 8K 的网站上。通过XMLHttpRequest API的异步请求使用最广泛,在超过 400K 的页面上有近 300 万次调用。考虑我们提出的新漏洞变体,之前的研究工作中有超过 44.7% 的API调用忽略了请求劫持威胁。
漏洞探测
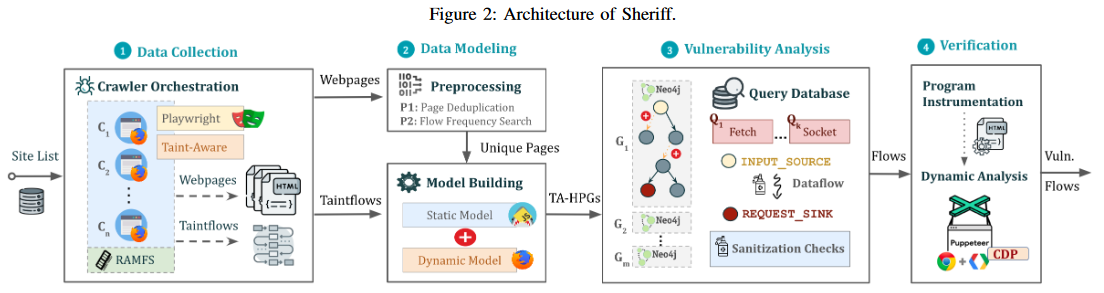
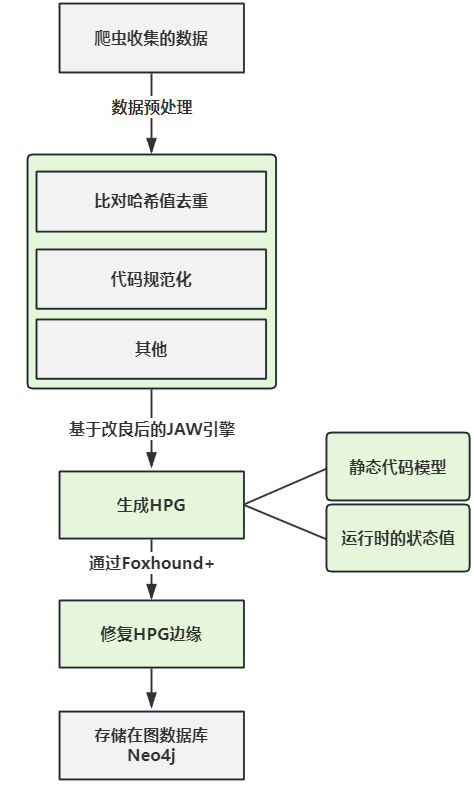
本文的研究者们开发出了一款动静态结合分析工具Sheriff,其主要基于4个主要部分:
- 数据收集模块:从网页收集
Web资源和动态污点流 - 数据建模模块:通过处理数据识别和建模独特的网页,并为其创建属性图
- 漏洞分析模块:
- 动态验证模块
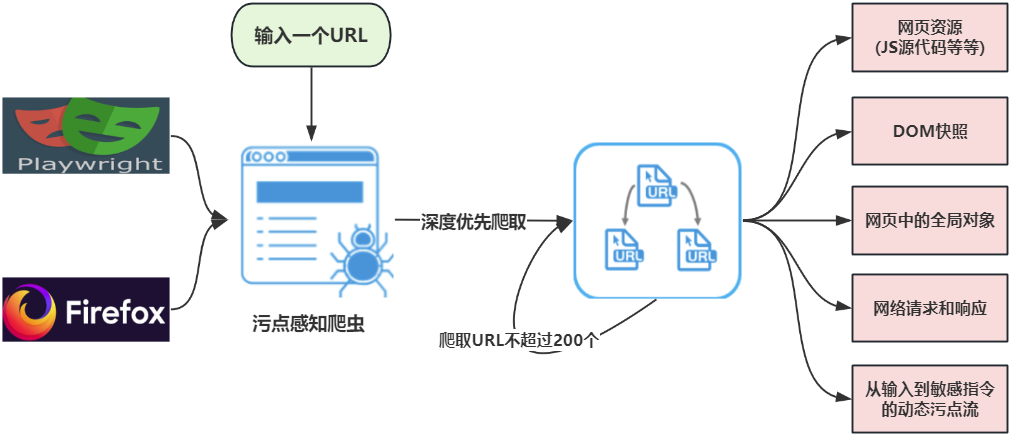
数据收集
本文的研究者们表示,数据收集的第一步是收集客户端的代码和运行时的参数值(比如DOM快照)。研究者基于playwright、Foxhound和Firefox Devtools开发了一个污点感知爬虫。同时由于Foxhound不支持所有的测试API,研究者们自己开发了支持,称为Foxhound+。
这个爬虫采用深度优先搜索的方式,对于一个输入,会爬取这个页面中的所有URL,然后爬取新URL中的所有URL,上限为200个。
在访问过程中,爬虫会收集以下信息:网页资源(例如脚本)、DOM快照、全局对象的属性、事件跟踪、网络请求和响应,以及从程序输入到安全敏感指令(例如请求)的动态污点流。
这个爬虫不会创建帐户或登录,因为手动创建和维护注册和登录脚本既脆弱又具有挑战性,特别是在处理数千个应用程序时。此限制符合大规模安全测试的最新技术,比如文章S&P2022中也是如此。
Playwright是一个开源的自动化测试工具,用于测试网页应用。它可以操控Chromium(用于Chrome、Edge等)、Firefox和WebKit(用于Safari)等主流浏览器,使我们能在不同浏览器中执行自动化测试。Playwright通过直接控制浏览器引擎(如Chromium和Firefox)来执行测试,而不是通过浏览器界面。这意味着Playwright可以直接操控浏览器引擎,执行更快速和稳定的测试。Playwright使用浏览器引擎自带的JavaScript执行环境和Web API来控制浏览器。
这个脚本会打开Chromium浏览器,访问example.com网站,获取网页标题并打印,最后关闭浏览器。
1 | |
Foxhound:一个在Javascript引擎和DOM中启用动态数据流跟踪的 Web 浏览器,基于Mozilla Firefox,它可用于识别客户端 Web 应用程序中不安全的数据流或数据隐私泄漏。
数据建模
鉴于爬虫收集的网页数据,出于效率和可扩展性的原因,Sheriff会执行数据预处理。例如,Sheriff通过比较SHA-256脚本哈希值对客户端代码进行预处理,以过滤掉几乎重复的网页,这使其能够专注于具有不同JavaScript代码的页面,从而减少程序分析的总体工作量。同样,Sheriff可以执行其他类型的数据预处理,例如先前工作中使用的基于(自定义)搜索的数据过滤或代码规范化。
删除重复的网页后,Sheriff创建被测客户端程序的属性图,捕获静态和动态程序行为,称为混合属性图HPG。 Sheriff使用JAW的扩展引擎实例化一个工作池来生成HPG。然后,这些HPG通过Foxhound+提供的污点流信息进行丰富,以修补由于静态分析缺陷而缺失的HPG边缘,最后存储在Neo4j图数据库中,我们可以查询该数据库进行安全测试。
HPG介绍
USENIX Security Symposium2021的一篇文章中提出了JAW框架,里面提出并详细介绍了HPG。
HPG这是一种基于图的规范JavaScript程序模型,用于JS代码的分析
JAW: Studying Client-side CSRF with Hybrid Property Graphs and Declarative Traversals
JAW,这是一个框架,可以利用混合属性图(JavaScript程序的规范混合模型)上的声明性遍历来针对客户端 CSRF分析现代Web应用程序。
要了解HPG,我觉得应该首先了解代码属性图CPG。参考文章
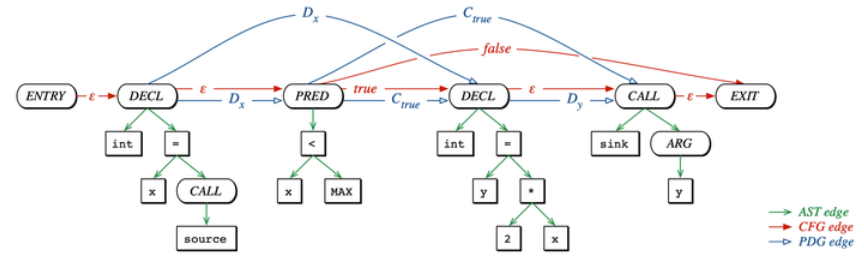
显然,CPG是一种图数据结构,它的主要思想如下:
CPG将多个程序表示(program representations)整合成一个CPG数据被存储在图数据库中- 通过
DSL在图数据库中遍历和查询CPG数据
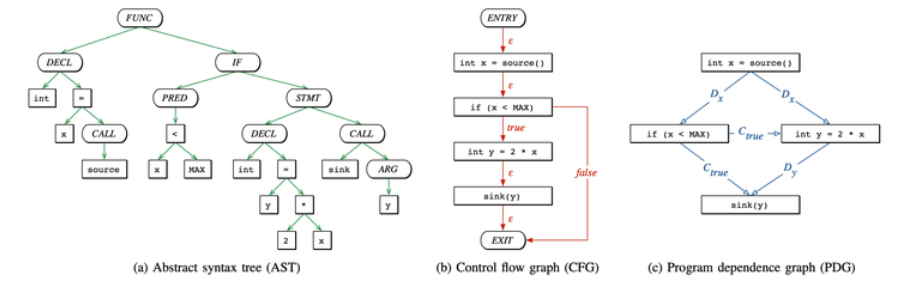
CPG 整合了 AST(abstract syntax trees)、CFG(control flow graphs)、PDG(program dependence graphs) 到一种数据结构当中。一个很知名的基于CPG原理的国产Java漏洞分析工具Tabby
抽象语法树(AST):以树的形式表现编程语言,树上的每个节点都表示源代码中的一种结构。AST一般作为源代码语法分析的重要思想,在编译原理这门课中应该会介绍。AST的应用其实是非常常见的,像是编辑器的错误提示、代码格式检查都用到了AST的原理。
程序依赖图(PDG):处理方法是以程序的控制流图为基础,去掉CFG的控制流边,加入数据和控制流边。包括了数据依赖图和程序依赖图。数据依赖图定义了数据之间的约束关系,控制依赖图定义了语句执行情况的约束关系。程序依赖图是一个有向图。
根据下面的程序画出的图:
1 | |
三者合一成为CPG:
下面我们可以详细讨论文章中提出的HPG:这是论文中存在CSRF攻击的样例代码
1 | |
原文中的HPG图:说实话,根本没有看懂哈哈哈哈。先放在这里吧。
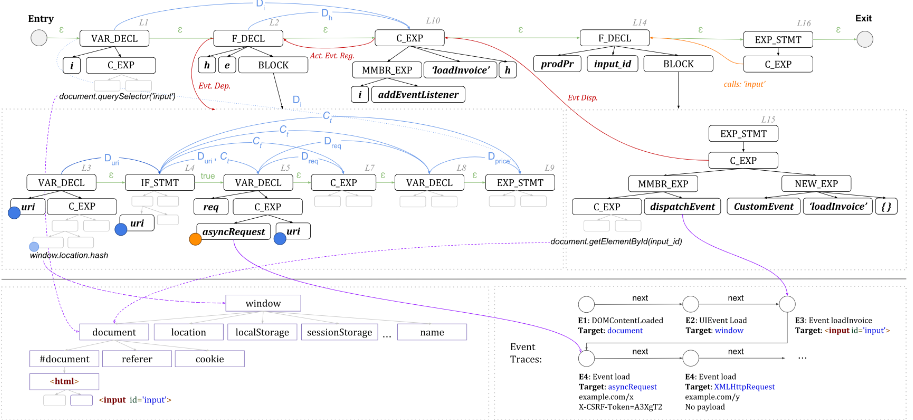
那么基于CPG的思想,HPG就是在JavaScript代码上的一个特化。简单来说,HPG是一种基于图的规范JavaScript程序模型,用于JS代码的分析。反正最后我们知道,HPG是客户端 JavaScript程序的统一表示,它将静态代码表示和运行时状态值集成到基于图形的结构中。
状态值是在执行过程中观察到的具体程序值,例如Web存储值和cookie。HPG集成了多种静态代码表示,即抽象语法树 (AST)、控制流图 (CFG)、调用图 (CG)、程序依赖图 (PDG) 以及事件注册、调度和依赖图 (ERDDG),它们分别捕捉程序的语法嵌套、执行顺序、函数调用关系、数据流和控制依赖性以及事件驱动的控制传输。HPG还包含语义类型,它们是分配给节点(例如接收器和源)的标签,用于捕获指令的语义含义。HPG编码为有向图,采用标记属性图结构,其中节点和边拥有标签和键值属性。
总之就是基于HPG,我们可以便捷地分析JavaScript的代码片段。
改进:Taintflow-Augmented (TA) HPGs
研究者们制定了HPG上的请求劫持漏洞检测任务,打算识别在页面加载时触发的请求发送指令,因为这些指令容易被攻击者通过程序输入操纵。
不幸的是,由于客户端JavaScript程序的动态特性,执行此类过程间可达性和数据流分析任务并非易事。虽然HPG状态值(即环境属性和事件跟踪)通过对具体对象快照(例如,指向分析和触发的分析)进行推理,有助于减轻许多 JavaScript静态分析缺点(例如,不精确的控制和数据流依赖性事件处理程序),但也不足以识别图中许多其他丢失的调用和数据流连接。
在本文中,研究者使用成熟的浏览器内动态污点跟踪,通过向节点添加补充边和标签(例如,标记可达性、语义类型和运行时变量值)来进一步增强HPG,从而重建缺失连接使得其在页面加载时可以访问,否则静态分析会错过这些。
我们使用Foxhound+收集从输入源到所有接收器类型的动态污点流,包括那些不是请求发送指令的指令,以便补充HPG中尽可能多的可能缺失元素。
具体来说,首先从Foxhound+中提取动态调用图和数据流图,并将它们分别与静态调用图和PDG合并。为了进行动态和静态图之间的匹配以进行合并,我们首先通过比较两个模型中的脚本哈希来确定指令或节点位于哪个脚本文件中,然后使用代码行来确定顶层(即CFG)该指令的HPG中的节点。
将动态数据流图与PDG合并时,如果缺少边,我们将创建数据依赖边,标签是传播其数据的污点流中报告的变量名称。相反,如果两个节点之间已经存在PDG边,我们会向该边添加一个标签,标记传播变量的运行时值。
类似地,当合并两个调用图时,如果缺少一条新边,我们将创建一条新边,并用调用的函数和参数名称以及函数调用的具体参数值对其进行标记。然而,当HPG中存在调用边缘时,我们只能通过添加调用站点参数的运行时值来丰富其信息。
最后,我们为所有源节点和接收节点添加标签作为语义类型,捕获这些指令的语义,例如,为读取document.URI值的指令设置类型RD_DOC_URL,然后在计算后传播到其他HPG节点的程序。
为了增强JAW的HPG生成,我们做了一些修改,解决了ES6支持不完整的问题,以改进控制传输建模和数据流分析。例如,我们使用Promise对象和setTimeout()回调添加了对异步操作的支持,提高了调用图和PDG边的精度。
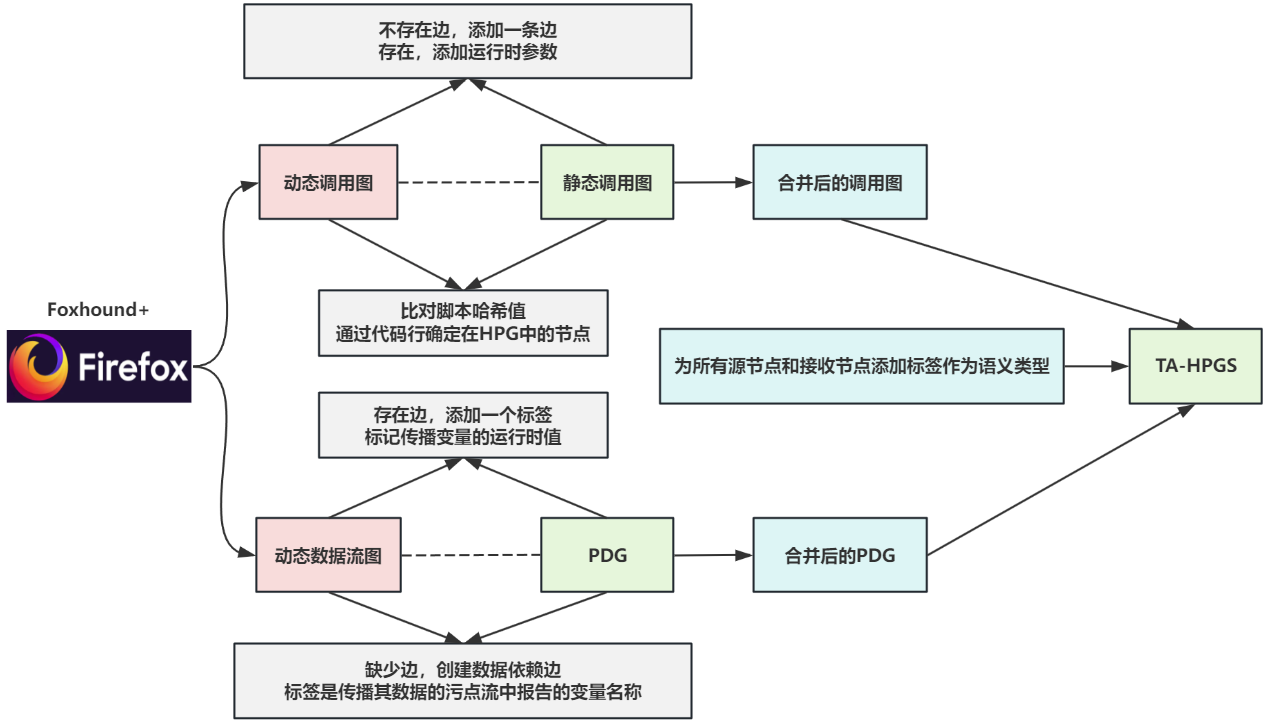
此外,我们应用了多种优化来提高可扩展性,例如处理PDG构建期间迭代构造的低效率问题,以及通过使用ineo创建协调器来并行管理Neo4j图形数据库。总体而言,这些修改解决了 JAW的几个缺点,使HPG的构建能够进行更精确的分析并提高了可扩展性。
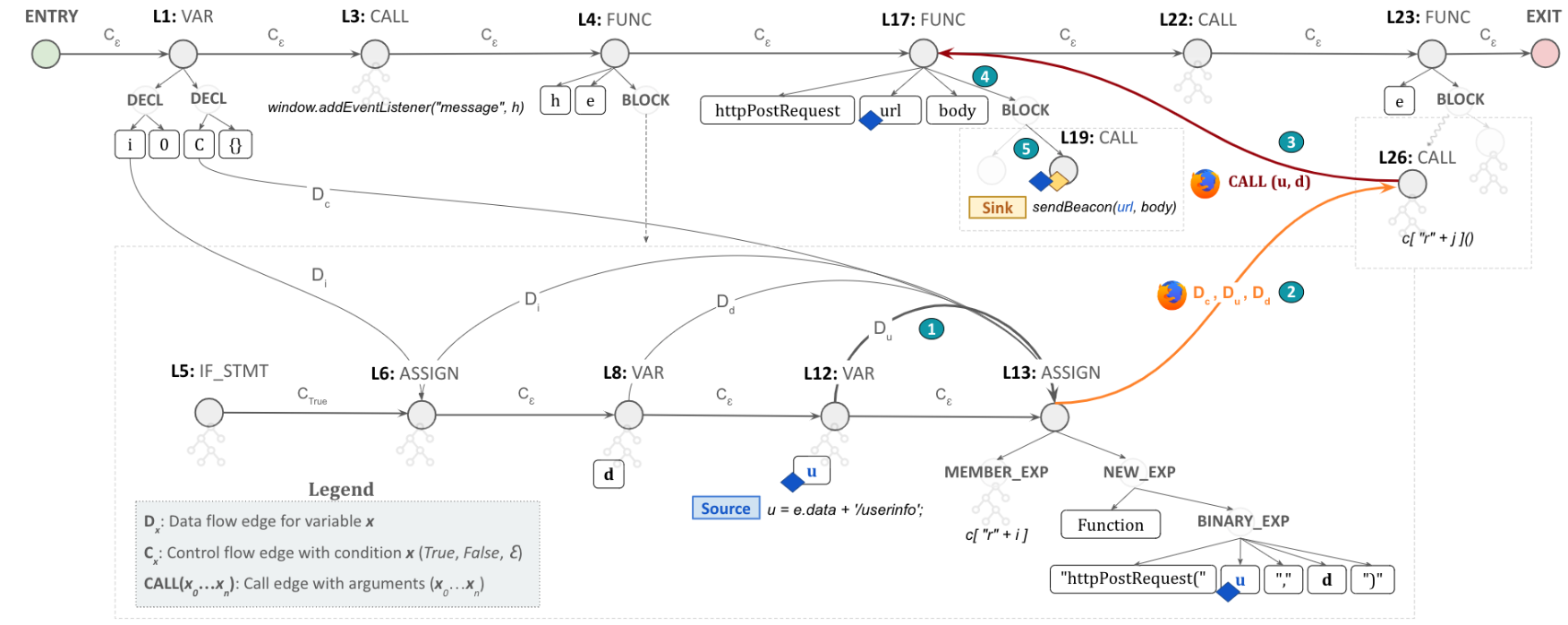
下方右侧的图显示了 Sheriff 为下方左侧中的代码生成的 TA-HPG,它增加了由于动态函数调用而丢失的 HPG 边缘。特别关注的是,Sheriff 使用 Foxhound+ 提供的动态污点流添加第 26 行中的调用表达式节点和第 17 行中的函数声明节点之间的调用边,以及 (ii) 从第 13 行中的赋值表达式到第 26 行中的调用表达式节点用于调用参数 u 和 d。
因此,TA-HPG 遍历现在可以从 L12 中的源节点开始,经过 L13、L26 和 L17 节点,最后到达接收器指令,该接收器指令拾取攻击者控制的值。
实例:
1 | |
漏洞分析
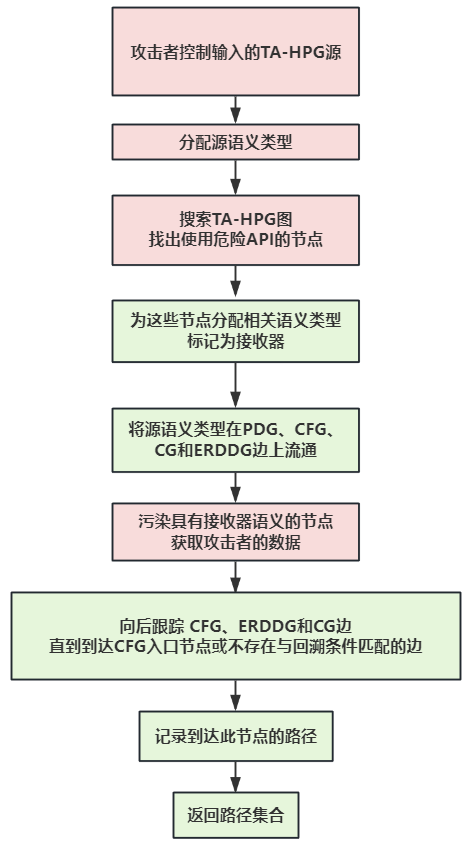
将客户端代码建模为TA-HPG后,研究者将检测请求劫持漏洞的任务定义为图遍历问题。具体来说,假设攻击者已经控制了某些指令的参数输入,现在搜索出页面加载时发送敏感请求的程序指令。
第一步,识别读取攻击者控制的输入的TA-HPG源,并为它们分配一个与JAW类似的相关语义类型,例如,我们为读取的指令设置一个名为 RD_WIN_LOC的标签通过window.location API获取URL。然后,给定用于发送请求的浏览器API列表,Sheriff 搜索TA-HPG以识别使用这些API的节点,并通过为它们分配相关的语义类型将它们标记为接收器,例如,标签 WR_ASYNC_REQ_URL是为写入异步请求的URL的指令设置的,例如XMLHttpRequest.open()。
最后,为了发现易受攻击的路径,Sheriff通过在PDG、CFG、CG和ERDDG边上将语义类型从源传播到接收器来执行数据流分析,其中具有接收器语义类型的节点被源类型污染,并且获取攻击者控制的值。
然后执行可达性分析,以检查易受攻击的路径是否可能对应于页面加载时执行的代码行。为此,它从污染源节点和sink node(污染数据的关键中转调用点)开始,向后跟踪 CFG、ERDDG和CG边,直到到达CFG入口节点或不再存在与回溯条件匹配的边,并选择污染源节点和sink node都存在的数据流。那么此接收器是可到达的节点。最终,该组件输出一组具有从源到请求接收器的潜在数据流的路径。
漏洞验证方法
研究者通过Playwright和Chrome DevTools Protocol来执行运行时监控,检测了负责发送请求的浏览器 API并拦截页面加载时发生的网络消息。为了最大限度地规避造成实际危害,验证模块检测请求API仅记录请求参数,而不实际向服务器端发送任何请求。对于每个实时页面,会首先比较其与数据集里的哈希值。如果相同的话,选择实时运行的页面进行监控。这样做是为了保证使用的是收集时的页面。
然后,对于每个请求劫持数据流,我们向相应的源输入一个无害的token,在由Playwright控制的检测浏览器中加载网页,并在客户端请求中搜索这个token以检查是否观察到了被操纵的输入。由于DOM环境不同,即使相同的页面,可能会有不同的执行结果,所有接近重复的页面也会测试每个候选数据流。
实证评估
表 3 总结了数据收集和建模步骤的结果。从 10K 种子 URL 开始,Sheriff在所有网站上总共获得了约1M个网页。每个网站的平均为103个页面。这些 100 万个页面包含大约 4610 万个脚本。页面重复数据删除将数据集的大小减少了约17%。也就是说,在总共 100 万个网页中,有 867,455个页面是唯一的
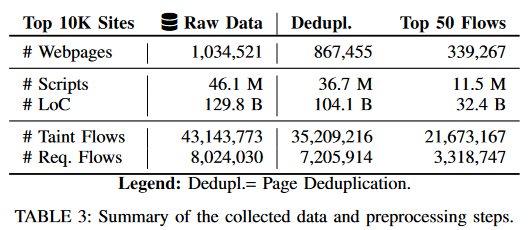
考虑到原始数据的庞大规模以及分析数十万个网页的需要,研究者通过将测试工作集中在每个网站中动态污点流频率最高的前 50 个页面上,进一步缩小了测试床的大小(源自输入源并到达请求发送接收器),这是基于这些页面包含漏洞的概率较高。总之,867K 个唯一页面包含约 720 万个动态污点流,这些流向请求发送接收器,我们将其用于页面选择。因此,867K 网页被过滤为 339,267 个页面。其中,Sheriff 提取了 11,544,754 个脚本和 21.6M动态污点流,用它们来丰富 HPG,以修复静态分析未发现的缺失连接。在这 2160 万个污点流中,有 3,318,747 个流包含请求发送接收器,这可以表明存在请求劫持漏洞。 Sheriff 总共平均处理 34 个脚本和每页 95K LoC,生成 339,267 个 TA-HPG。
在可被劫持的各种类型的请求中,异步请求最为普遍 (85%),在 905 个站点中有超过 172K 个实例。有趣的是,窗口导航请求(Window Navigation Requests)是第二常见的(8.2%),占 365 个站点。在另一个极端,被劫持的推送请求和 EventSource 发生的频率最低,分别仅影响 25 个和 3 个站点的约 0.3% 的请求流。最后,被劫持的 WebSocket劫持和顶级请求(Top-level Request)表现出中等程度的流行程度,相当于总共约 6% 的易受攻击的数据流。
新漏洞类型和变体构成了请求劫持的很大一部分(即 36.1%)。首先,新漏洞类型占已发现案例总数 23.6 万个的 14.2%(35,159 个)以上。其中,Sheriff 验证了 10,925 个网页和 439 个站点的 28,827 个易受攻击的数据流,突显了新漏洞的广泛存在。然后,21.9% 的请求劫持是我们考虑使用新浏览器 API 的新变体。
发现的劫持造成的危害中最常见的是客户端 CSRF,其中 96% 的漏洞(即 196K)可以被滥用。然而,48.5% 的可劫持请求也可能被滥用进行信息泄露,因为攻击者可以控制请求发送到的端点,从而窃取请求正文中包含的敏感信息,例如 CSRF 令牌、PII、推送端点和加密密钥。最不常见的后果是推送订阅上的持续 DoS,占漏洞总数的 0.2%。其他常见后果是客户端 XSS 和开放重定向,总共影响 10.1% 的页面。最后,4.2%的漏洞可能导致WebSocket和EventSource的跨站点连接劫持。
通过修补漏洞检测所需的缺失 HPG 边缘(即混合数据流路径),帮助静态分析识别 17.9K 额外数据流。然而,表 3 强调了纯动态分析的一个关键挑战:报告的污点流规模很大,其中大部分不受攻击者控制(参见表 10)。相反,静态分析能够检测到 66.2K 数据流。因此,动态和静态分析的结合可能是有利的。动态分析通过补充 HPG 边缘(例如调用图)来增强静态分析,而静态分析有助于消除攻击者无法控制的虚假污点流(例如由于输入验证)。
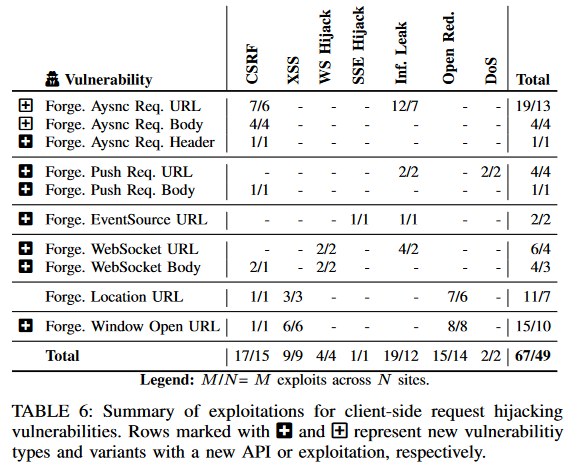
表 6 总结了在调查过程中发现的攻击。我们总共在 49 个网站上创建了 67 个概念验证漏洞,产生了深远的影响,例如 CSRF、客户端 XSS、开放重定向以及跨各种流行平台和功能的敏感信息泄漏。值得注意的是,我们发现了 Starz 电影流服务中的帐户接管漏洞、Microsoft Azure 中的用户 VM 删除、Google DoubleClick 和 VK 中的任意重定向、DW 和 BBC 中的帐户设置操纵、Indeed 中的工作申请篡改、通过 WebSocket 的数据泄露JustWatch 和 Forbes 中的 EventSource 劫持、Reddit 中 PushManager 订阅的 CSRF、Yoox 购物网站中推送通知的持久客户端 DoS,以及 TP-Link 中的客户端 XSS,仅举几个例子。其中,24 个站点的总共 33 个漏洞属于我们工作中提出的新漏洞类型。我们建议感兴趣的读者参阅§A.2,了解已确认攻击的案例研究。
防御策略评估
本节讨论 RQ3,我们在其中审查和评估针对客户端请求劫持漏洞的现有对策的采用情况和有效性。我们系统地调查了学术文献、W3C 规范和 OWASP CheatSheet Series,寻找经典的反 CSRF 对策和那些可以减轻客户端请求劫持的防御措施。总的来说,研究者确定了 10 种不同的请求伪造防御措施,并根据执行方(即 Web 应用程序或浏览器)将其分为两大类。

我们的分析发现,约 47% 的易受攻击的数据流没有任何输入验证检查,这表明开发人员很大程度上没有意识到与控制客户端请求相关的风险。
window.open()在新窗口中打开易受攻击的目标页面,COOP可用于将浏览上下文与同源文档隔离。例如,如果在新窗口中打开一个诚实的、带有COOP的跨域页面,则恶意打开的页面将不会引用它,从而阻止攻击者设置窗口名称,或向新窗口发送postMessages,这在turn可以防止伪造这些输入生成的请求。我们发现大约 7% 的请求劫持数据流可以通过COOP缓解,因为它们依赖于窗口名称、文档引用者和postMessages来提供程序输入。然而,我们观察到,只有 ∼1.9% 的网页实施了COOP,而且令人惊讶的是,没有一个表现出请求劫持数据流的网页采用了这一政策,这呼吁人们提高对COOP的认识。
累了😥